Rabbitmq |
您所在的位置:网站首页 › rabbitmq ready一直有数据 › Rabbitmq |
Rabbitmq
|
【概述】 消息、队列有持久化与非持久化的属性,持久化的消息会在磁盘上存储,而非持久化的消息在内存中存储。然而消息并非固定按照持久化属性仅在磁盘或内存中存储。当内存占用达到一定水位时,内存中的存储的消息会被置换存储到磁盘上,以释放更多的内存;当消费者消费消息时,存储在磁盘上的消息又会被读取加载到内存中。 消息的存储包括消息内容的存储和消息索引信息(在队列中的位置、消息的状态、属性、元数据信息等)的存储,并且消息内容与消息索引是分开进行存储的(3.5.0版本开始,允许消息嵌入到索引中随索引信息一并存储)。这就意味着消息内容、消息的索引信息可以分别在内存与磁盘上进行存储。 但具体要怎么存储,以及什么时候在内存与磁盘的存储中进行切换,这就需要有个模块来进行统一的管理调度。 在rabbitmq中,每个队列都会有一个backing_queue模块,镜像队列与非镜像队列的这个模块是不同的,但最终都包含了rabbit_variable_queue模块,这个模块就负责消息的存储调度。 【概念与内存结构】 在web管理控制台指定队列的页面上,队列详情中分别显示了队列total,ready,unack,in memory,persistent,transient paged out的信息。 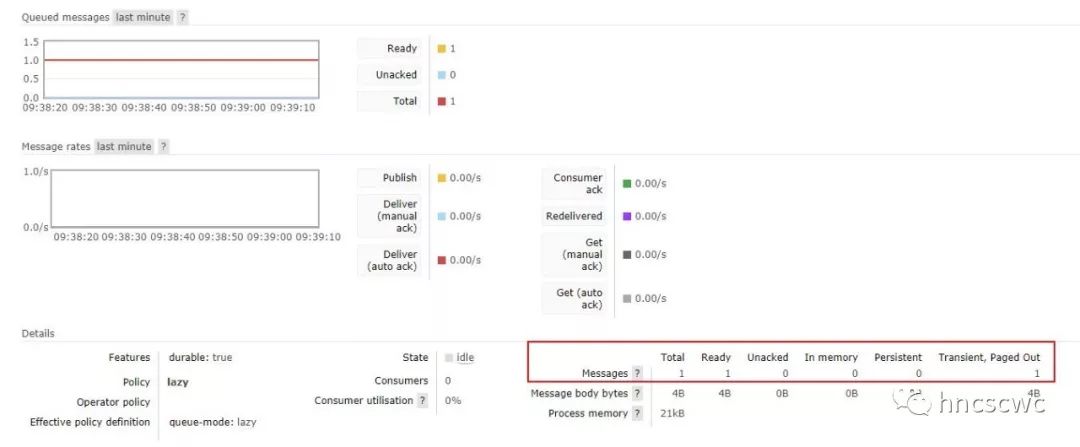 这些信息具体的含义如下: ready:已发送到队列,但还未发送给消费者的消息,也就是仅执行了publish的消息。 unacked:已发送给消费者但还未收到消费者ack的信息,即执行了publish和delivery的消息。 total:ready与unacked消息的总和。 in memory:表示在内存中进行缓存的消息数。 persistent:表示在磁盘上存储的消息数。 transient, paged out:表示非持久化的,但实际存储到磁盘上的消息数(可能因为内存达到一定水位触发的置换,也可能是队列为lazy模式,即便是非持久化的消息也存储在磁盘上了) 对于ready的消息,rabbitmq引入了alpha、beta、gamma、delta几个阶段,来对应消息内容与索引信息在内存磁盘存储位置的变化。具体定义为: alpha:消息的内容与对应的索引信息均在内存中存储 beta:消息的内容仅在磁盘中存储,消息的索引信息在内存中存储 gamma:消息的内容仅在磁盘中存储,消息的索引信息同时在内存与磁盘中存储 delta:消息的内容与索引信息都仅在磁盘中存储 具体实现时,设计了4个队列(Q1/Q2/Q3/Q4)来对应这几个阶段。其中Q1与Q4存储alpha阶段的消息,Q2与Q3存储beta和gamma阶段的消息;由于delta阶段的消息其消息内容与索引信息均在磁盘中存储,因此并没有使用队列来对应delta,而仅仅是记录在delta阶段的消息的起始序号,实际消息数与delta中的非持久化消息个数。 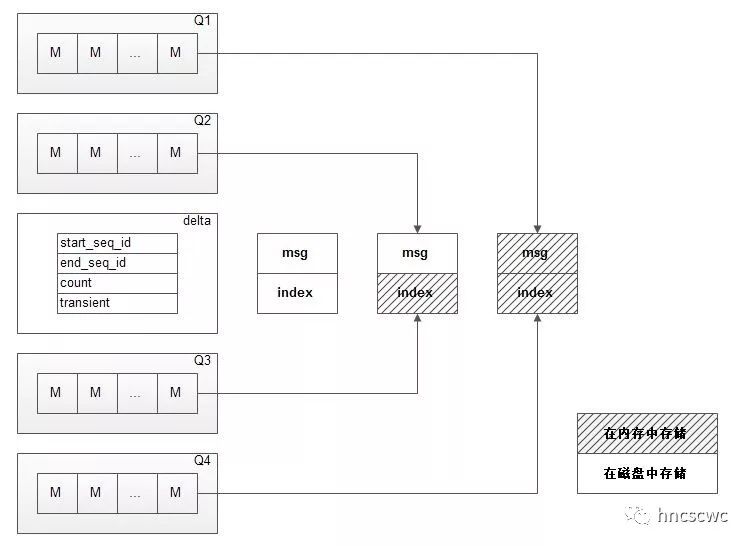 这里有一点要说明:消息的内容与对应的索引信息在内存中缓存,并不意味着这个时候消息内容与索引信息就完全不在磁盘中存储了,这取决于消息是否持久化,即某个时刻,持久化的消息其消息内容与索引信息同时在内存与磁盘中存储。同样,消息的内容仅在磁盘中存储也并不是绝对的,这取决于消息的存储位置是msg_store(消息内容与索引分开存储)还是queue_index(嵌入索引一并存储)。 考虑到上述几个因素,完整的情况如下表所示: 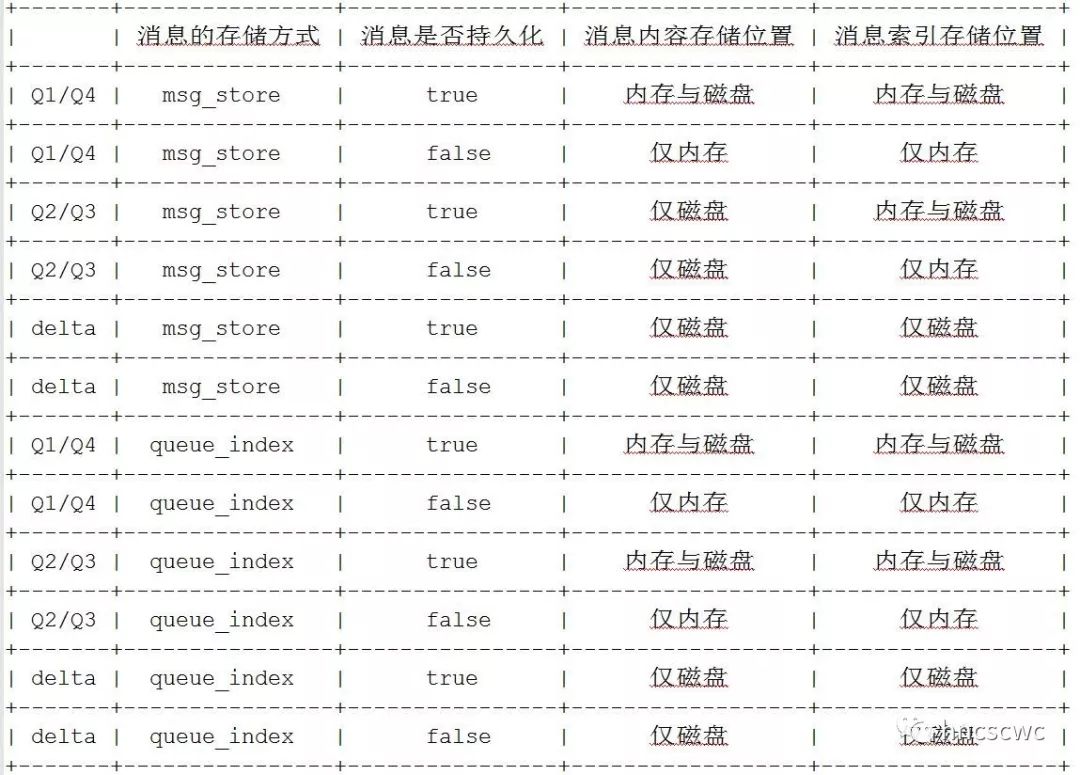 对于unack的消息,设计了三个树结构来存储这些消息。在树结构中,以消息在队列中的序号作为key,消息的完整信息(包括消息内容和索引信息)作为value进行存储。三个树结构分别存储不同类别的消息,具体为: ram_pending_ack:采用msg_store的存储方式,同时消息内容还在内存中缓存。 disk_pending_ack:消息内容不在内存中缓存(只有采用msg_store存储方式的消息,消息内容才可能不在内存中缓存)。 qi_pending_ack:采用queue_index的存储方式,同时消息内容在内存中缓存。 从ready转换到unack的消息,会从前面说的几个队列中移出,转存到这几个树结构中进行存储。 从上面的描述可以归纳下:本质上还是在围绕消息的publish、delivery、ack进行区分,所以消息有ready、unack之分;然后考虑消息内容与消息索引可分别存储在内存与磁盘上,所以逻辑上对消息分成了不同的几个类别(阶段),实现上设计了不同的存储方式分类存储。 【相关流程】 前面提到了几个队列来缓存ready状态的消息,通常情况下,消息在这些队列中的流向是:Q1-->Q2-->delta-->Q3-->Q4,这个流向可以这么理解: 消息publish到队列时,消息进入Q1(消息内容与索引均在内存中存储)消息不断的publish到队列,内存占用到达一定程度,部分消息进入到Q2(消息内容仅存储到磁盘上,索引还在内存中缓存)更多的消息publish到队列,内存的使用更上一个档次时,消息进入delta(消息内容与索引信息都仅在磁盘中存储)当有消费者消费消息时,批量读取一部分消息,还未推送给消费者的消息从delta进入到Q3当内存不那么紧张时,Q3中的消息转存到Q4中当然这里只是举形象一点的例子进行说明,实际情况下并非每条消息都会按顺序走完每个流程,例如消息可能会直接跳过前面几个流程,进入到Q4(因为Q4和Q1属于同性质的队列),消费者消费消息时,先从Q4中读取消息。 有了上面的铺垫,rabbit_variable_queue模块中消息的生产消费流程就很好理解了,其大概流程为: 消息publish到队列时,如果Q3为空,则将消息缓存到Q4中;如果Q3非空,则将消息缓存到Q1中消息delivery给消费者时,先从Q4中获取消息;如果Q4为空,则从Q3中读取消息;如果Q3也为空,则从delta中读取一部分数据放入Q3中,再从Q3中读取消息在某个时刻,为了减少内存的使用,会将消息写入到磁盘,减少内存中缓存的消息数,具体操作及流程为: 限制unack消息的缓存 对所有unack的消息,将消息内容写入磁盘;同时对于存储方式为msg_store的消息,清除在内存中的缓存(对于消息嵌入索引信息一并存储的消息,由于索引信息还在内存中缓存,因此对应的消息内容也还是在内存中缓存)。 限制ready消息的缓存 这里会分两个阶段进行 1) 一阶段是将消息内容写入磁盘,具体为:如果delta为空,则将Q1的消息转到Q3中存储,否则将Q1的消息转到Q2中存储;然后将Q4中的消息转到Q3中存储。和上面一样,对于存储方式为msg_store的消息,在内存中缓存的消息内容会被清除。 2)第二阶段是将消息的索引信息写入磁盘,也就是将Q2,Q3中的消息转到delta中存储。(注意:为了防止一次写入磁盘的量太大从而将队列的进程阻塞,因此每次将Q2,Q3中消息转到delta中存储时,会对数量进行一定的限制)经过上面的处理,在内存中缓存的消息都被写入到磁盘上,这样也就将内存释放出来了。 【触发时机】 前面提到了为了降低内存的占用,会进行一系列的处理动作来减少内存的占用,有几种情况会触发进行。 定时器触发检测在rabbitmq内部有一个专职对内存进行检测的进程。每个队列进程会设置一个定时器,定时器超时后,根据超时时间段内消息publish、delivery的速度,给生产者的confirm,消费者的ack速度,以及在内存中缓存的ready消息数,unack消息数来推算出下一个时间段内将会在内存中缓存的消息数,并将这个推算出的缓存消息数上报给内存检测进程。 内存检测进程周期的得到所有队列的统计情况,然后根据当前rabbitmq的内存占用情况,判断是否需要进行paging(将消息写入磁盘,减少内存的占用),如果需要进行paging,则根据当前内存占用情况,当前所有队列缓存的消息数重新计算出允许缓存的消息总数,并将这个值告知所有队列。 每个队列拿到这个允许在内存缓存的消息总数后,根据自身实际的速率得出本队列在内存中允许缓存的消息数,最后按照前面讲述的流程,进行内存释放处理。 可通过http接口获取队列的详细信息,详细信息中包含了Q1-Q4队列中的消息数;此外,target_ram_count就是该队列在内存中允许缓存的消息数。 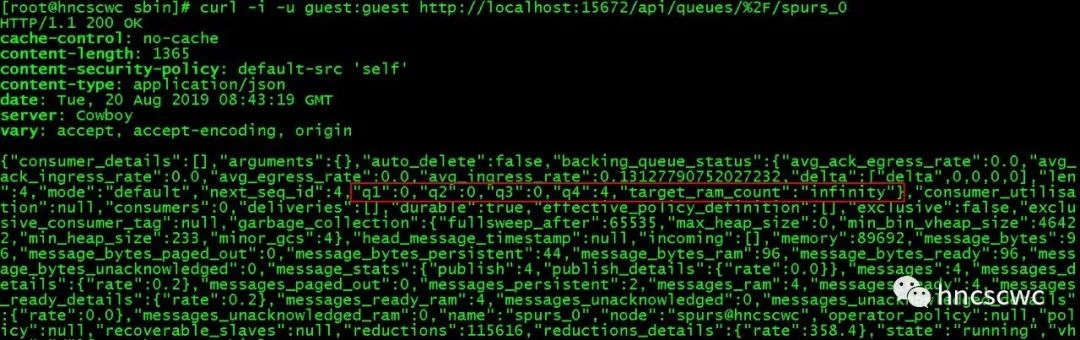 从上面的流程,我们可以推出另外一个逻辑:队列每次触发内存释放处理动作时,并不是一股脑的将所有缓存的消息全部写入磁盘,而是减少在内存中缓存的消息数,即还是会有一部分消息在内存中缓存,这个数量就是根据内存占用情况,队列的实际速度重新计算出来的。 另外,这个值还会影响到索引文件刷磁盘的频率(因为消息的索引信息写磁盘时也并非每条都同步刷到磁盘文件中,会有一定的缓存机制,详见《rabbitmq——索引文件的读写机制》)。极端情况下,消息的任何一个操作(publish、delivery、ack)都会触发索引文件同步将对应的日志数据刷到磁盘上。这种情况下,性能必然是非常低的。 发送指定条数的消息后触发检测每publish指定条数的消息到队列后,会进行判断。如果此时实际缓存的消息数小于允许缓存的消息数,那么不做任何处理;否则需要触发内存的处理动作。这个指定的条数是可以进行配置的,默认是1000条。 【lazy队列】 rabbitmq从3.6.0引入lazy队列,lazy队列尽可能的将消息存储在磁盘上,减少内存的占用。只有被消费者消费时,才按需从磁盘加载到内存中。 上面讲述的概念与流程几乎都同样适用于lazy队列,不同的点在于:lazy队列仅仅会用到delta和Q3。消息publish到队列时,消息直接进入delta中,也就是不在内存中进行缓存;消息delivery给消费者时,才从delta读取部分到Q3中。 同样,当内存占用到一定水位时,lazy队列的处理就是将Q3队列中的消息重新存储到delta中。 下图是一个lazy队列publish和delivery消息后的对比,可以结合上面讲述的流程来对比分析下。 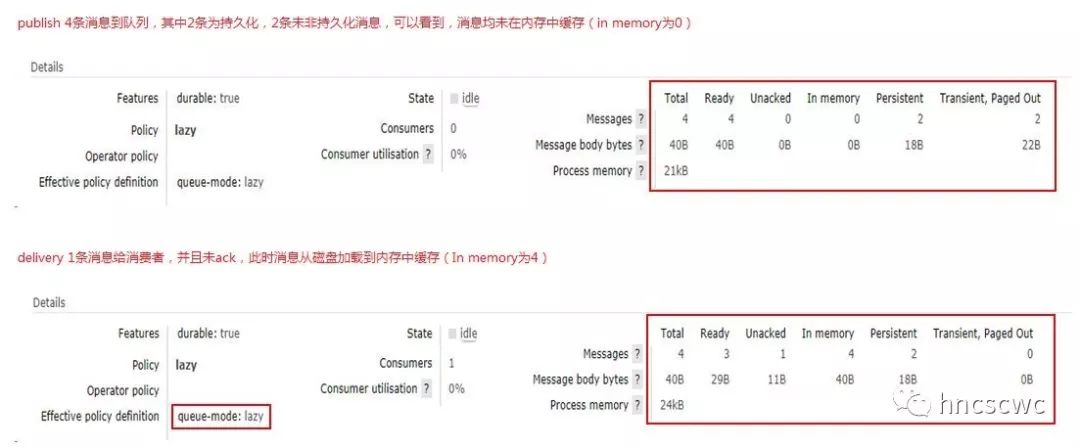 【总结】 本文总结了rabbit_variable_queue对消息在内存磁盘存储调度的相关原理。 |
【本文地址】
今日新闻 |
推荐新闻 |